Recently, I was asked about monitoring Microsoft DHCP IP Address Pools using Log Insight to alert when the pool was exhausted and DHCP requests were failing. There are a couple ways to do this, but I'd like to cover two as a demonstration of getting a bit fancy with your alert queries and it paying off big time!
First off, Microsoft DHCP Servers write their events to a log file - at the end of the day.... so we can parse that file for an Event ID of 14 to see when we ran out. This is easy to do as shown below using Event ID 11 (DHCP Renew) as an example. The regex is simple but unfortunately we get the information way too late!
Enter the Log Insight Agent's ability to read Windows Event Logs! As your DHCP Server starts running low on available addresses in a certain pool it starts to throw warnings in the System Event Log with an Event ID of 1376 that state what percent is currently used and how many addresses are still available.
It would be really cool if we could have Log Insight fire off an alert if these messages showed that we were above 90% used, right? But it's text... how do we do math on text in log messages? The good news is that not only can you accomplish this; it's easy to do!
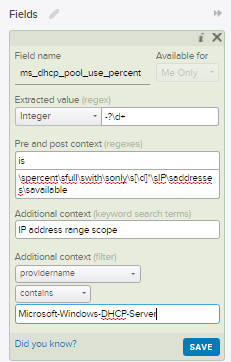
First off, we need to create an Extracted Field that allows us to treat the value of percentage used as an integer. Simply highlight the number and select "Extract Field"
Now you will have a dialog box on the right hand side that allows you to define what exactly makes this extracted field. Let's look into these options with a bit of detail...
Extracted Value: For this use case you will be leaving this field alone as any changes will remove the type of "Integer". This can be problematic if you have numbers with a comma (1,000) but the engineering team is aware of it. For now, leave it as is.
Pre Context: This is a regex defining what comes before our desired value. In this example it is the word "is" from "is 85 percent full".
Post Context: The same as pre-context just for the regex after the value. It's important to make both the pre and post context detailed enough that they only apply to this exact context/event type. It's better to go a bit overboard with the regex than make it too simple. Just make sure to keep some room available in the text for the next item, keyword search terms....
Additional Context (keyword search terms): In this section you'll want to add in keywords that are found in the data outside of your regex. In this case my keywords match strings found before my pre-context regex. These are important as they help improve your query performance and lighten the load on your Log Insight Server.
Additional Context (filter): Why search through 2 billion events when you only need to search 100? That's exactly why you should also use filters to help narrow down where this Extracted Field will apply. Your users will thank your for keeping the performance on your Log Insight Server at peak efficiency!
Now that we have our Extracted Field defined we can modify our initial query to have an additional filter that says "ms_dhcp_pool_use_percent" (Name of our new Extracted Field) is greater that X%! This is demonstrated in the below screenshot where everything below 86% is dropped, and consequentially, would never be alerted on.
Lastly we need to define an alert off of our new query. Select the little red bell and select "Create Alert from Query"
Here we define the new alert properties for when our alert query returns a result.
And with that you're done!
Special thanks to my co-worker
Simon Long for bringing up the need for this cool use case!