Monday, September 25, 2017
Blog moved....
Please checkout https://blog.lottabytes.com as it is the new location I will be using.
Thursday, June 8, 2017
Deploying vRealize Log Insight (vRLI) via API
I've finally gotten around to upgrading the vRLI Configuration Management and Audit Tool to handle the full deployment process as well as clustering! Let's take it for a spin to see what the new features allow us to do!
1. First we need to deploy the vRLI VMs from OVA that can be downloaded from my.vmware.com. Once they have been fully booted and you see them serving the following webpage we can start. You can close your browser at this point; nothing is required here other than we are checking to make sure that they are fully booted.





1. First we need to deploy the vRLI VMs from OVA that can be downloaded from my.vmware.com. Once they have been fully booted and you see them serving the following webpage we can start. You can close your browser at this point; nothing is required here other than we are checking to make sure that they are fully booted.

2. The tool uses a JSON configuration file that you can see a sample of by running the program with a "-d" flag or browsing the first part of the Python (my recommended approach). You can also generate a simplified version by calling the wizard using a "-b" flag. For now, I'm going to create my configuration file based on the sample in the documentation with a single Master Node under the "fqdn" key and 2 Secondary Nodes under the "nodes" key in my JSON file. This means that when the script is done I will have a new, 3 node vRLI Cluster.

Let's kick off the program and tell it to use my configuration file by running:
python li-json-api.py -f ctest.json -r
Note: the "-r", otherwise known as"remediation enabled" flag is required since building a new cluster requires changing settings. If you forget this step, don't worry, it will remind you. Also, remember that when building a new node/cluster you must supply the "admin" user's credentials.
Now, what's going on behind the scenes in the newly added code?
1. The script detects that the Master Node is in pre-bootstrap mode and is awaiting the initial configuration.
2. We complete the initial bootstrap process as partially described in the vRLI API documentation. The missing piece here is that the documentation never tells you that you need to explicitly use port 9543 for these calls. During deployment is the only time this is required.
3. We license the first node which allows us to add additional nodes.
4. We add each secondary node and authorize it with the Master and repeat until complete.
The process looks like this:

The rest of the operations that we do to configure the various settings in vRLI are all old functionality but none-the-less, important.
The code can be run as often as you would like without any ill effect. Our approach is to store our configuration files in source control and have the job run on a reoccurring basis to catch any unauthorized changes and automatically remediate configuration drift. Below is an example of me re-running the job against the cluster we just built. Because it is matching the desired state, no changes are executed against the cluster.

Let's say that our vRLI Cluster is growing (excellent!) and we want to add another node to it. No worries, just deploy a new VM and add the new IP/FQDN to your JSON configuration file as a new "node" and run the script again!

As you can see, the original nodes are recognized as already in a cluster and the 4th node (.40) is discovered as a new node and added to the cluster.
Friday, October 14, 2016
Find DN of my user in AD
Sometimes you need to know what your DN is in Active Directory and want a quick way to find it without powershell scripts or AD related tools. This command is the best way I've see thus far to accomplish it:
whoami /fqdn

Wednesday, October 5, 2016
Getting Fancy with Log Insight Alerting (aka. Monitoring DHCP pools via logs)
Recently, I was asked about monitoring Microsoft DHCP IP Address Pools using Log Insight to alert when the pool was exhausted and DHCP requests were failing. There are a couple ways to do this, but I'd like to cover two as a demonstration of getting a bit fancy with your alert queries and it paying off big time!
First off, Microsoft DHCP Servers write their events to a log file - at the end of the day.... so we can parse that file for an Event ID of 14 to see when we ran out. This is easy to do as shown below using Event ID 11 (DHCP Renew) as an example. The regex is simple but unfortunately we get the information way too late!

Enter the Log Insight Agent's ability to read Windows Event Logs! As your DHCP Server starts running low on available addresses in a certain pool it starts to throw warnings in the System Event Log with an Event ID of 1376 that state what percent is currently used and how many addresses are still available.

It would be really cool if we could have Log Insight fire off an alert if these messages showed that we were above 90% used, right? But it's text... how do we do math on text in log messages? The good news is that not only can you accomplish this; it's easy to do!
First off, we need to create an Extracted Field that allows us to treat the value of percentage used as an integer. Simply highlight the number and select "Extract Field"

Now you will have a dialog box on the right hand side that allows you to define what exactly makes this extracted field. Let's look into these options with a bit of detail...



First off, Microsoft DHCP Servers write their events to a log file - at the end of the day.... so we can parse that file for an Event ID of 14 to see when we ran out. This is easy to do as shown below using Event ID 11 (DHCP Renew) as an example. The regex is simple but unfortunately we get the information way too late!

Enter the Log Insight Agent's ability to read Windows Event Logs! As your DHCP Server starts running low on available addresses in a certain pool it starts to throw warnings in the System Event Log with an Event ID of 1376 that state what percent is currently used and how many addresses are still available.

It would be really cool if we could have Log Insight fire off an alert if these messages showed that we were above 90% used, right? But it's text... how do we do math on text in log messages? The good news is that not only can you accomplish this; it's easy to do!
First off, we need to create an Extracted Field that allows us to treat the value of percentage used as an integer. Simply highlight the number and select "Extract Field"

Now you will have a dialog box on the right hand side that allows you to define what exactly makes this extracted field. Let's look into these options with a bit of detail...
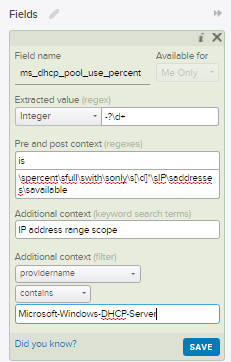
Extracted Value: For this use case you will be leaving this field alone as any changes will remove the type of "Integer". This can be problematic if you have numbers with a comma (1,000) but the engineering team is aware of it. For now, leave it as is.
Pre Context: This is a regex defining what comes before our desired value. In this example it is the word "is" from "is 85 percent full".
Post Context: The same as pre-context just for the regex after the value. It's important to make both the pre and post context detailed enough that they only apply to this exact context/event type. It's better to go a bit overboard with the regex than make it too simple. Just make sure to keep some room available in the text for the next item, keyword search terms....
Additional Context (keyword search terms): In this section you'll want to add in keywords that are found in the data outside of your regex. In this case my keywords match strings found before my pre-context regex. These are important as they help improve your query performance and lighten the load on your Log Insight Server.
Additional Context (filter): Why search through 2 billion events when you only need to search 100? That's exactly why you should also use filters to help narrow down where this Extracted Field will apply. Your users will thank your for keeping the performance on your Log Insight Server at peak efficiency!
Now that we have our Extracted Field defined we can modify our initial query to have an additional filter that says "ms_dhcp_pool_use_percent" (Name of our new Extracted Field) is greater that X%! This is demonstrated in the below screenshot where everything below 86% is dropped, and consequentially, would never be alerted on.

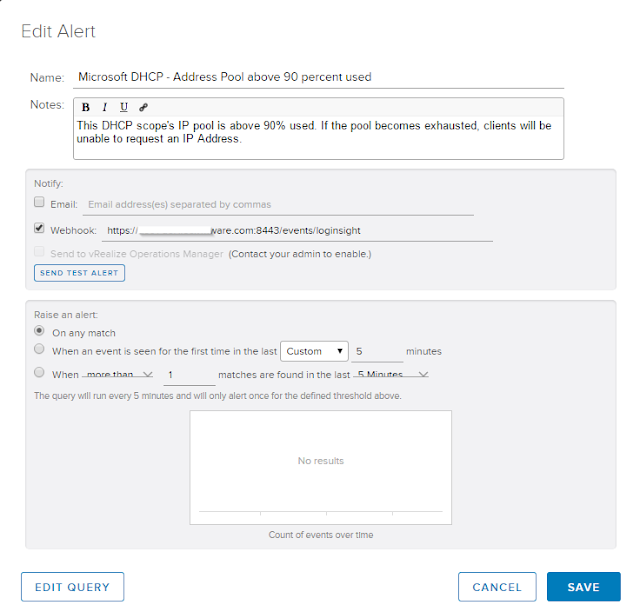
Lastly we need to define an alert off of our new query. Select the little red bell and select "Create Alert from Query"

Here we define the new alert properties for when our alert query returns a result.

And with that you're done!
Special thanks to my co-worker Simon Long for bringing up the need for this cool use case!
Thursday, September 22, 2016
Corrupt Microsoft SQL Database Log in AlwaysOn High Availability Group (AAG)
We recently ran into an issue with one of our environments where the Microsoft SQL Server experienced corruption in the database log. This issue is usually discovered when you attempt to create a new backup and it fails with the message "BACKUP detected corruption in the database log"
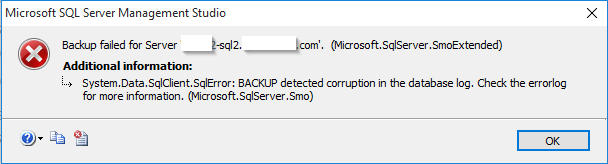
Resolving this issue is normally fairly easy (set the database from a Full Recovery Model to simple and then back again) but it gets a bit more complex when you database is replicated via an AlwaysOn High Availability Group. Here are the steps to fix it (assuming no other databases are in the AAG).
1. Remove Secondary Replica - First we need to stop replication to the secondary replica. To do this we are going to connect to the primary node in our cluster and right click on the SECONDARY replica. Then we select "Remove from Availability Group" and follow the wizard.

2. Remove Database from AAG - Next we need to remove the database from the AAG by right clicking on it under the Availability Databases folder and selecting "Remove Database from Availability Group"

At this point you should have your primary node as the only member of the AAG with no databases associated. At this point you are going to delete the database from the SECONDARY node. Your secondary server should now have no replicas, no availability databases and no database.
3. Next we need to change the remaining copy of the database on our primary node from Full to a Simple Recovery Model by right clicking on the database and selecting properties > Options.

4. Next we need to do a full backup of the database.
5. Repeat the steps in #3 but in this case change it from simple back to the original Full Recovery Model.
6. Backup the database again.
Now we are ready to re-add the secondary replica
7. On the primary server right click on the Available Replicas folder and select "Add Replica..."

Next you will need to select the "Add Replica" button and will be prompted to connect to your secondary server.

After this you will want to configure your replica. In our case we have selected to have the secondary copy of the database as readable as well as enabling automatic failover.

In the next screen you will need to configure your sync preferences. We are using a Full sync which requires a file share accessible by both SQL Servers. Using this file share SQL will run a backup and place it on the remote share and the secondary node will restore the database from this initial backup.

Follow the wizard and verify that everything passes

After this you can track the progress of the backup/restore/sync

With that you should have a working AlwaysOn Availability Group again!
Friday, September 16, 2016
FreeTDS and Microsoft SQL Server Windows Authentication - Part 1
I've been trying to get the Zenoss SQL Transaction Zenpack working so that we can use Zenoss to run SQL queries for specific monitoring purposes and ran into a few things that might be worth sharing.
Using tsql for troubleshooting
Zenoss, among many other tools uses pymssql to connect to your SQL Servers; and pymssql uses FreeTDS behind the scenes. If you can't get pymssql to work them you can go a layer deeper to see if you can find the issues. In my case I have the following configuration:
Fedora Server 23
freetds-0.95.81-1
pymssql-2.1.3
First off, FreeTDS uses a config file at /etc/freetds.conf that has a [Global] section and examples for configuring individual server types. This is important because you need to use TDS version 7.0+ for Windows Authentication to work.
If we try to connect using the diagnostic tool tsql (not to be confused with the language T-SQL) without changing the default TDS version or adding a server record in the config file our attempts will fail

To fix this you can either:
Change the Global value for "tds version" to be 7+ (sounds like a good idea to me if you only have MSSQL):

or you can add a server record for each Microsoft SQL Server and leave the global version less than 7.




It's basically a simplified version of the example on the pymssql web page, but will prove if pymssql and MSSQL Windows Authentication is working or not.
-------------BEGIN Code
import pymssql
print('Connecting to SQL')
conn = pymssql.connect(server='server.domain.com', user='DOMAIN\\username', password='Super Secret P@ssW0rds', database='master')
print('Creating cursor')
cursor = conn.cursor()
print('Executing query')
cursor.execute("""
SELECT MAX(req.total_elapsed_time) AS [total_time_ms]
FROM sys.dm_exec_requests AS req
WHERE req.sql_handle IS NOT NULL
""")
print('Fetching results')
row = cursor.fetchone()
while row:
print(row[0])
row = cursor.fetchone()
print('Closing connection')
conn.close

Using tsql for troubleshooting
Zenoss, among many other tools uses pymssql to connect to your SQL Servers; and pymssql uses FreeTDS behind the scenes. If you can't get pymssql to work them you can go a layer deeper to see if you can find the issues. In my case I have the following configuration:
Fedora Server 23
freetds-0.95.81-1
pymssql-2.1.3
First off, FreeTDS uses a config file at /etc/freetds.conf that has a [Global] section and examples for configuring individual server types. This is important because you need to use TDS version 7.0+ for Windows Authentication to work.
If we try to connect using the diagnostic tool tsql (not to be confused with the language T-SQL) without changing the default TDS version or adding a server record in the config file our attempts will fail

To fix this you can either:
Change the Global value for "tds version" to be 7+ (sounds like a good idea to me if you only have MSSQL):

or you can add a server record for each Microsoft SQL Server and leave the global version less than 7.

The catch to second method is that when you do your queries you will have to call the name as shown in the config file (in this case us01-0-srs1) and you cannot use the FQDN or it will fail because it defaults back to the Global setting. This method also creates overhead in managing the list of MSSQL Servers in the freetds.conf file.

Either way, at this point you should have tsql being able to query your MSSQL Servers using Windows Authentication

Getting started with pymssql
To make sure that pymssql is working I threw together a quick bit of python that allows you to connect using Windows Authentication

-------------BEGIN Code
import pymssql
print('Connecting to SQL')
conn = pymssql.connect(server='server.domain.com', user='DOMAIN\\username', password='Super Secret P@ssW0rds', database='master')
print('Creating cursor')
cursor = conn.cursor()
print('Executing query')
cursor.execute("""
SELECT MAX(req.total_elapsed_time) AS [total_time_ms]
FROM sys.dm_exec_requests AS req
WHERE req.sql_handle IS NOT NULL
""")
print('Fetching results')
row = cursor.fetchone()
while row:
print(row[0])
row = cursor.fetchone()
print('Closing connection')
conn.close
-------------END Code
After filling in the details on your MSSQL Server you can simply run it and get the results

Part 2 will cover the Zenoss specific aspects of this...
Friday, August 26, 2016
Zenoss and ServiceNow Integration - Custom Fields and Values
Our Zenoss instance is integrated with ServiceNow so that our support organization can open an incident with the appropriate event details at the click of a button from the Zenoss Events Console. The workflow for this looks something like the below flowchart that I just threw together.








.

The problem however is that our Zenoss instance was not following through in the last step after incident resolution and closing out the associated Zenoss Event. Because of this we were missing alerts on re-occurring issues since the event was in an acknowledged state. By default the Zenoss Incident Management ZenPack looks at the incident_state field for values 6 and 7 to indicate a closed event. However, our ServiceNow instance uses the underlying state field that is inherited from the task table that the Incidents table is built on top of instead of incident_state.

You can find out what field you are using by right clicking on the State label and either seeing the "Show - ''" or clicking on "Configure Label" which will show you the associated table
Next we need to find out the appropriate values associated with the state so that we can update Zenoss. Open the Task table under "System Definition - Tables".

Then open the state column. (You can do this by clicking on the information button).

Next you will want to filter the results down to the Incident table and you will be able to find the integer values for your state.

In this case I want an incident with a state value greater than 3 to be considered from a Zenoss point of view to be "closed" and monitoring to be re-enabled by moving the Zenoss event from an "Acknowledged" state to "Closed".
Now, to make the change on our Zenoss server we need to create a snapshot of the Zope container, make the changes to the IncidentManagement ZenPack configuration and commit the snapshot so that the changes are persistent when the zenincidentpoll container is restarted.
From my Control Center I'm going to run the below command to start:
serviced service shell -i -s update_closed_sn zope
After that I can modify the appropriate file changing the values to match what I've discovered in the previous steps:
vi /opt/zenoss/ZenPacks/ZenPacks.zenoss.IncidentManagement-2.3.16-py2.7.egg/ZenPacks/zenoss/IncidentManagement/servicenow/action.py

After saving the file and exiting the Zope container using "exit" we now need to commit the new image using:
serviced snapshot commit update_closed_sn
After committing the snapshot you need to restart your zenincidentpoll container from the Zenoss Control Center UI and then your changes will be live and you should be able to close an Incident in ServiceNow and have Zenoss automatically close the associated Zenoss event as seen in the below event notes.

Hopefully that helps!
Subscribe to:
Posts (Atom)